
Like many developers, I’ve spent a lot of time thinking about objects. I started doing object-oriented programming (OOP) in 1989, and was arguably still doing it up until 2012. The concept of objects arose in GUIs and simulations, where it is natural to think about sending message to things. Over time though, the idea of messages took a back seat to the idea of locking data up in little containers where each class provides a namespace of functions to operate on it.
With OOP, classes hide all the data. Every object provides its own methods on the class, which makes up a library for what you’re allowed to do with that class—but only that class. It doesn’t give you great functions that work across everything.
Working with databases from an object-oriented language leads you to create object relational mapping layers. That is essentially inserting a tool that knows how to work with objects in order to get data out of them and into the database. This tool calls the right methods on those objects to get the data out, creates an insert statement for the relational database and puts the data in the statement.
Looking at this now, we can see that this entire complex layer of software only exists because we chose to keep our data in objects. Our object relational map tool is a solution to a problem that we created. And, we created the problem because we were embedded in an old paradigm.
 Porsche, Emily Baron, https://flic.kr/p/npnUQb
Porsche, Emily Baron, https://flic.kr/p/npnUQb
The majority of our work is with data. Services accept data on the wire, process it and either put it in a database or put the transformed result back on the wire. The whole approach of OOP - writing and annotating classes rather than simply working with the data as data - introduces fragility into the system. In contrast, working with data as pure data streamlines development and enables change. Data orientation powers the new, maneuverable microservices architectures.
For example, in Clojure, you deal with data as data. You don’t try to force the data into an object-oriented semantic. Clojure has functions that work on any kind of sequential data, any kind of associative data and any kind of set data. Instead of writing a class that has ten or fifteen methods, you get to use hundreds of functions. (Over 640 in clojure.core alone.)
So, it doesn’t matter if you’re using a map to represent a customer or an order or an order line item, you use the same functions to operate on all of them. The functions are more general, so they are more valuable because you can apply them more broadly.
When you first start working with Clojure, you’ll be tempted to bring along some of the OOP baggage. But it’s a good idea to stop and rethink what it is you want to do. You need to reconsider why we did certain things in the OOP world, and whether we need to continue doing them in a data-oriented world.
To demonstrate the contrast, here’s an example of what you might do to add a new table if you’re working with a relational database. You put together a string that says something like:
"CREATE TABLE FOO (ID INTEGER NOT NULL PRIMARY KEY, NAME VARCHAR(256),...)"
The string buries the data. The data is no longer available for further processing. Once the data is in the string, I can't do anything with it except send it to the database server. String bashing opens the door to security vulnerabilities. Strings create fragility. As if that weren't enough, the time and energy it takes to generate strings only to have the database parse them is wasted. The process only exists because I can’t directly send the database the attributes that I want to create.
The same thing in Datomic looks like this:
[{:db/id #db/id[:db.part/db]
:db/ident :foo/id
:db/valueType :db.type/long
:db/cardinality :db.cardinality/one
:db/unique :db.unique/identity
:db/doc "Unique identifier for Foos."
:db.install/_partition :db.part/db}
{:db/id #db/id[:db.part/db]
:db/ident :foo/name
:db/valueType :db.type/string
:db/doc "A human-readable name for a Foo."
:db/cardinality :db.cardinality/one
:db.install/_partition :db.part/db}]
You can take a look at the schema reference if you're interested in the details.
To me, the most interesting part is what I can do with that metadata. In most databases, data and metadata are entirely separate worlds. You've got one language for manipulating the database schema and a totally different one for manipulating the contents of the database. The query language can only query contents and cannot touch schema. Datomic puts data and metadata on the same level. Suppose I wanted to make a documentation generator that ran across my code and documented the schema. Can you imagine scanning for every string, then parsing the string to see if it is a SQL statement, then extracting the details of the tables? Absolutely not. Can you imagine mapping a function across a list of maps, to extract the :db/ident and :db/doc keys? Easiest thing in the world.
This is why I like working with Datomic. My transaction is data, just a vector of vectors or a vector of maps. What I get back as a result is data, a set of tuples. If I want to look at any of the built-in attributes of any of the attributes I’ve added—any of the metadata—I just do an ordinary query and get back ordinary data. My query is specified as data. Results come back as data.
I eliminate the loop of generating and parsing strings. I can use data in my program and send the data directly to the database. This creates a great simplicity: I never need an object relational mapping layer. If I need to look at something, I can interact with it through the REPL or through a debugger and I just see the data, I don’t see some opaque driver-specific object like I would with JDBC.
Data orientation comes into play when we’re building services or interacting with services. Anytime we need to use JSON or XML to communicate with something, the typical approach in Java or C# is to write a class that represents the unit of data that we’re passing around. This is when versioning gets difficult and people say, “it's hard to support multiple versions of your API.” Again, it’s a problem we’ve created for ourselves by choosing the object-oriented approach. Working with data as data, it becomes easier to work with multiple versions, and easier to manage change, which builds antifragility.
With Clojure, it’s very easy to support multiple versions of our API. In fact, it so easy, we can even have an API about APIs. Now, our data-orientation approach takes everything up a level. By using data rather than classes or annotations we give ourselves the ability to “go meta” with no more difficulty than writing things (straight?). If we wanted to do that in Java, we would need to build some kind of a new language that emitted Java as its byte code. We don’t need to do that with Clojure.
By focusing on the data, and not to doing a lot of the data modeling inherent in the old OOP paradigm, the data becomes very easy to represent, open up and unlock. For example, it’s easy to make the data available to mobile and web applications used by other systems via APIs.
With a data-driven microservice, instead of writing code that describes the data that you’re going to send via JSON, or writing code that has annotations all over it to turn it into REST paths, we simply send a chunk of data to a service. That data describes a data format and it describes end points to expose via http (nonREST). This data orientation paves a direct path to maneuverable microservices and increased business value.
In a previous post, I asserted that by working with a maneuverable microservices architecture and open source technology and tools such as Clojure and Datomic, a pair of skilled developers could create a meaningful service in minutes or hours versus days and weeks.
My colleague Paul deGrandis has done some compelling work in the area of data-driven microservices. Working with Consumer Reports, who was in the process of reviewing new technologies and platforms, Paul proposed and developed three proof-of-concept (POC) systems, all produced with Clojure, ClojureScript and Datomic. The last POC rebuilt an existing system, providing a benchmark for comparison.
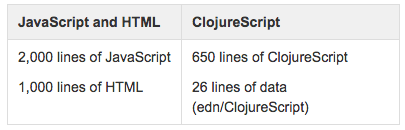
In terms of project metrics, two developers designed and implemented the engine/runtime/tool/platform that was then used to rapidly prototype additional concepts in 3-4 weeks. Brand-new applications can be created in minutes or hours, and result in 10-50 lines—compared to the days/weeks/months and thousands of lines required by the old paradigm. To learn more about Paul's work with data-driven microservices, see his talk from Clojure/Conj 2014, Unlocking Data-driven Systems.
What about scaling? When I started moving from objects to functional programming, my big fear was that I'd be back in the days where changing a 'struct' in a header file broke code in totally different modules. Objects did afford us the luxury of hiding decisions and ignoring them. Of course, instead of coupling to a structure definition we coupled to a class definition, but at least parts of it could be made private. Wouldn't functional programming land us back in the days of limited program complexity due to data structure coupling?
Nothing exists in a vacuum. The data oriented, function style is becoming popular at the same time as microservice architectures. This is not a coincidence and it is not totally driven by the necessities of multicore programming. Rather, we have discovered that there is an upper bound on scaling a system up via object-oriented programming. Too many companies have created golden anchors out of their multimillion line code bases. We are uncovering new ways to structure applications that enforce even stronger encapsulation and decision-hiding than object-oriented programming. In doing so, we are getting back Alan Kay's original ideas: it's about the messages.
You can think about each microservice as being an autonomous actor–a black box. You can send it messages. It sends messages back or it sends messages to others. We are implementing these with functional programming, but that is invisible from outside the black box. We choose data orientation inside the box because it makes the code smaller and more disposable.
Data orientation unlocks the value of your data and is a means to gaining high leverage. You can think of high leverage as the difference between steering a bus and steering a sports car. The same small steering wheel turn gives you a much bigger change in direction with the sports car. When you’re working with high leverage, you don’t have to put as much investment in to get the same functionality or value out. Because your code is simpler and easier to create, it can be considered disposable. And with disposable code, you don’t feel the compulsion to keep it, like you would with the old paradigm boat anchor projects. It all adds up to this: data orientation drives antifragility, enabling you to change individual vectors, and your entire organization more swiftly.
Read all of Michael Nygard's The New Normal series here.